Just a bunch of Party Analysts
We had a theory: we can better serve analysts by bringing the data to them, not the other way around. In this post we explore how we experimented with extending Google Workspace to support analyst activities in the lab.

Introduction
Having spent time in complex, information-heavy environments which cultivated both a sense of frustration AND new exciting power word combinations in an attempt to illustrate our frustration, we wanted to try something different.
Given the green field nature of our business, we were in a position where we could experiment with different options, test some ideas and find out what sticks.
In this post, we present a high-level overview of our knowledge management platform - SporeCore - which helps us in our analytical work. We walk through why we built it, the basic features, the failings and how it holds up overall. We look forward to presenting some more detailed views of this work as it evolves in the near future.
To understand SporeCore, we want to quickly recap why we’re here. Many services start with the premise that their users are ignorant or missing something obvious. However, we consider that the vast majority of decision makers find themselves where they are because they are smart and competent at their jobs.
The problem, we premise, is time. Executives and decision makers don’t have enough hours in the day to give due consideration to every decision, or to be instant experts in every subject matter that crosses their desk.
Early on we decided that we would try to help them via two key capabilities: easy to consume reporting, and insightful briefings.
To build these products, we needed a platform where we could save and tag the information we consume during our research.
We needed an information pipeline.
Congratulations! You now have two problems.
Anyone who has spent any time in the design, development and deployment of analyst or intelligence pipelines will tell you that they all start with good intent but end up wildly complex and difficult to use.
The goal of our pipeline is to ingest data from various sources, enable them to be reviewed (and maybe weighted with a confidence level or tagged), before being stashed in a pool for analyst consumption during intelligence product authoring.
This can seem like a straightforward process initially, but as soon as you start ingesting data from various sources - you quickly realise data is messy and managing it is a pain in the ass.
There are many great off-the-shelf solutions out there, especially for specifically focused analyst work (such as cyber intelligence), however we’re a scrappy startup with a limited budget so they were out of reach.
We also don’t like to assume there isn’t a better way of doing things. We love to experiment.
Based on experience, we also knew that if you do manage to get a working pipeline and system, you then end up with a secondary, unexpected problem - the analysts hate your tools.
It’s not for lack of capability within the tools that analysts dislike them, it’s that they prefer to work within their native environments. This commonly takes the form of either a spreadsheet (CSV files), a Jupyter notebook (using Python to hack on CSV files) or their text editor of choice (such as Emacs or VSCode to vertically extract columns from the CSV files). An exaggeration I know, but analysts are gonna analyse.
So you risk a bunch of effort (and money) to have data routinely exported to the analyst environment for crunching.
So we decided to try something different. We decided, rather than bringing the analyst to the pipeline - we will bring the pipeline to the analyst.
Getting Proof of Concepty With It.
To accurately research emerging topics, we need to collect and consume as much as we can on a given topic. We also want to ensure that anything we find can be accessed and read by anyone else on the team.
Source material we routinely consume in the development of our work includes research papers, news articles, blogs, books, YouTube videos and Open Source code - basically a melting pot of multiple formats and disparate quality.
At the lab we use Google Workspace for our Email and document collaboration. There is no real significant reason for this other than wanting to be able to operate cross-platform (Linux / MacOS) with as little sysadmin overhead as possible and easy to understand billing. At this early stage of the lab we wanted to focus our effort on work for customers rather than maintaining internal systems.
Being Workspace users gives us access to the often under-utilised benefit of the Google AppsScript development environment. You may have never heard of it, but AppsScript lets you extend your Workspace environment via supported APIs to automate and extend Gmail, Google Calendar, Google Docs and Google Chat. Similarly to Microsoft Office Power Apps, you can automate all aspects of what you would normally do in the Workspace environment with code.
For our proof of concept, we wanted to ingest all of the above mentioned intelligence sources, save them in a searchable database and then reference them as we work.
This use includes within our expedition logs, which are Google documents wherein we outline our objectives and research notes over multiple-weeklong sprints. To support the way we work, we ideally wanted to be able to leverage smart chips and building blocks.
Over 50 years old and going strong.
Our first point of ingestion comes in the form of emails. Tech that is over 50 years old at this point.
Given the recent resurgence of mailing lists and newsletters, emails can be an amazing source of curated, summarised and relevant information. Given we are focused on multiple topics, we needed a way to ensure that not only can we separate and tag by ‘topic’, but also let analysts search previous emails in their native tooling.
After a bit of virtual whiteboarding, we decided to implement the following workflow:
- For each topic, create a Google Group with a topic alias. Subscribe analysts who are interested in that topic. Enable ‘submissions’ from outside sources.
- Create an Inbox that can be subscribed to the various groups for automation.
- Monitor the inbox for new messages.
- Process new messages, tag, summarise and save the content.
- Mark the original message as read indicating it has been processed.
- Present a summary for the message into the general intelligence channel on Google Chat.
In theory, this means each analyst can directly monitor emails if they choose, view the message summaries in chat at their leisure, search Google Groups for specific words and ensure searches within SporeCore for keywords will match known emails.
Surprisingly, this turned out to be a really straightforward approach to our email ingestion.
To begin, we started a fresh AppScript project and created a function to process messages. It in turn uses our pre-existing experimental Workspace functions to use Google Gemini to create an AI summary of the message, save the entry to SporeCore and notify the intelligence team of the new entry.
Once hooked into a timer for execution (currently every 30 minutes), we found that the last step was to subscribe our user to a bunch of relevant topics.
This process has been running for a number of months, has processed hundreds of messages and successfully been processing the subscribed newsletters and ‘tidbit’ emails sent to the various topic addresses without any concern.
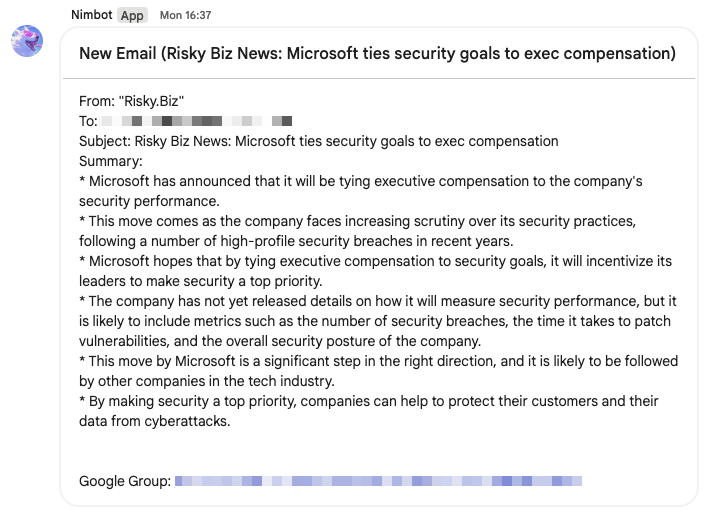
Nimbot?
Nimbot!
As you can see in the screenshot above, Nimbot is our helpful little bot that handles the messages for staff, inspired by our fluffy office mascot, Nimbus the Japanese Spitz.
Nimbot is responsible for all Chat interactions about SporeCore including some auxiliary utilities for users.
Our goal was to enable users to swiftly and easily save and search intelligence items. Beyond the standard formats, these might be as simple as copy and pasted text from analysts. So, Nimbot is the Google Chat app whose job it is to handle user requests.
Nimbot monitors for direct messages and in certain channels (such as our intel channel) for slash commands. Once one is received, they get to work. For example we can ask for help:
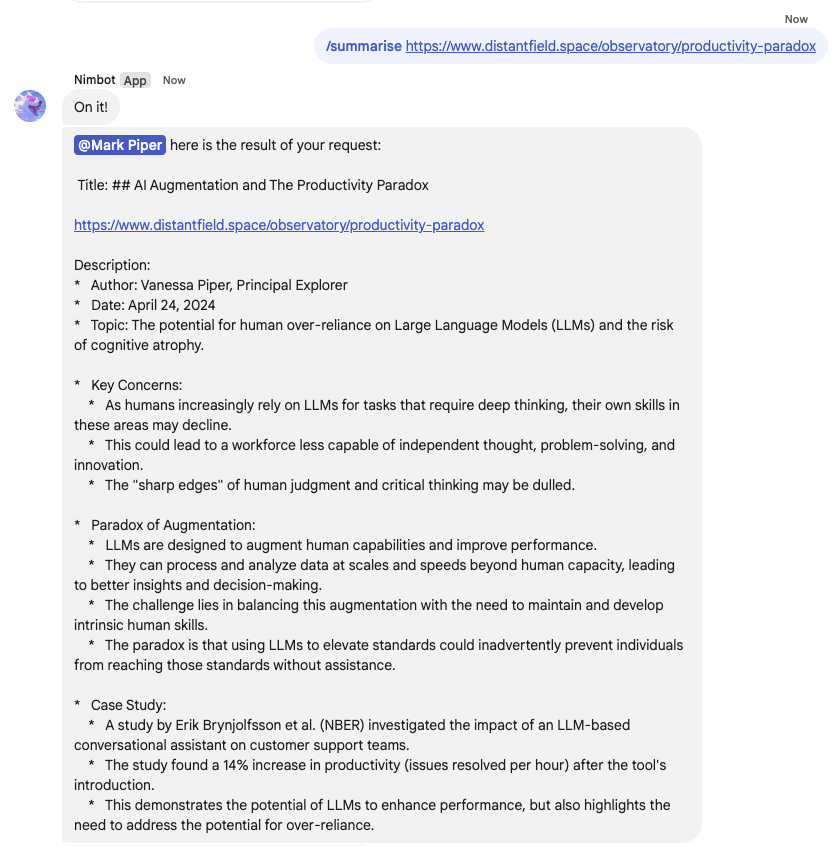
Or, we can request a summarisation of a interesting article:
And naturally, we can save an item to SporeCore. In this case an online article, but it could be a PDF, Google Drive attachment, Youtube video etc.:
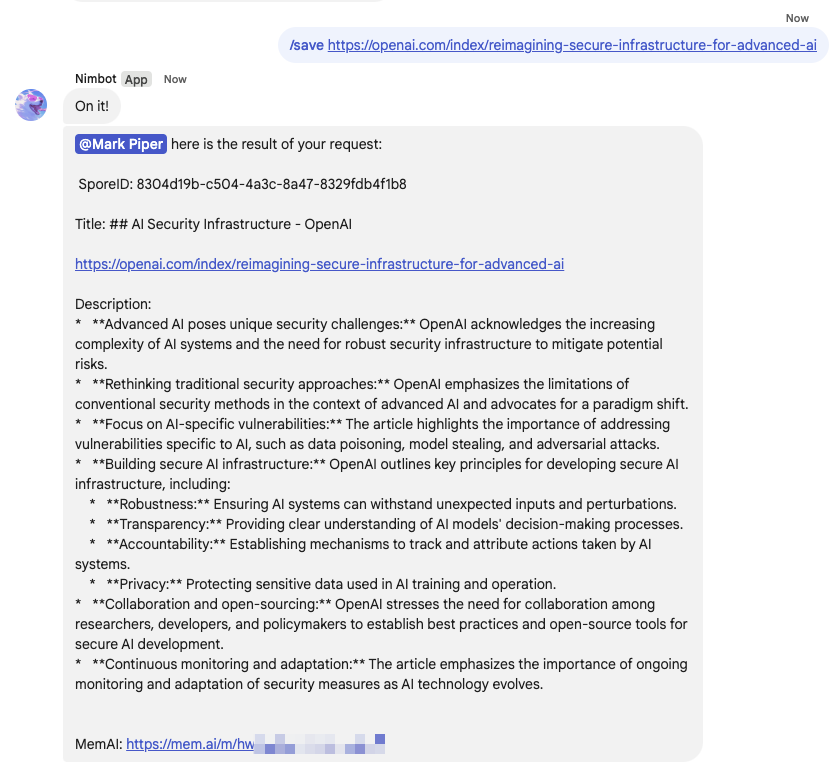
So what just happened here? Nimbot did the following:
- Nimbot submitted the save request, and associated argument (the article) to the processing queue.
- Our AppScript requested the website and underlying HTML.
- We took a best guess effort to extract the relevant content (i.e the <article> tag).
- We submitted the extracted content to Google Gemini to summarise the data.
- We saved the data to the SporeCore database.
- We notified the analyst of the result.
Simple but helps us with a number of key aspects for use in the future. For example, we have the article and a good title saved in the DB. We also have generated a summary of the content. We do this for two reasons - First, attempt to maximise the relevant keywords that we might search for retrospectively. Second, much of the content we save (including research papers) are long and complex and we want to reduce the size of the data we save and therefore have to manage.
One of the goals of the Nimbot approach was to reduce friction for analyst submissions. Often, while on the go we might read a link and think that it will be useful later, but we don’t want to have to jump through hoops to save it into the SporeCore database. Because it’s based on a pre-existing chat application, we can simply make it so the ‘share’ interface on mobile devices can be used to send a link to Nimbot.
To support this, direct messages to Nimbot default to the /save slash command. This means that a user can seamlessly submit an entry and move on with their day. For example:
Embedded legacy video removed during security hardening.
What’s with the mem.ai link?
Mem.ai is part of an experiment for us. We’re written a lot about AI, and it’s no secret that we embrace it here at the lab for analytical tasks. Beyond the Google Gemini use above, we wanted a way to query our own notes with a chat interface.
Given all our entries are publicly sourced and no classification requirements exist we could experiment a little with our data.
In the spirit of moving fast and breaking things, we decided to leverage the mem.ai API to mirror our SporeCore entries so we can test with chat access.
In theory, this should work great! In practice however (and much to our frustration), Mem.AI is still some way away from creating a performant and well-synced application suitable for day-to-day use. It is yet another entry on a very long list of companies who announced their vision first, and built it second resulting in incomplete and broken functionality (we talk more about this trend in our next report).
That said, we believed in the vision and still do - and hope the team at Mem.AI reaches stability soon so we can move it from an occasional experiment to daily usage with our data.
You Keep Using That Database Word
Yes we do, don’t we?
Our initial implementation of SporeCore tried to be a little too clever, and leveraged managed database services on Google Cloud. The problem with this solution is that it was absolute overkill for our use.
When we talk about collecting content, we’re talking across a very small number of users. The complexity (and script execution costs) that were involved to authenticate from AppsScript to Google Cloud and then construct and execute queries felt like the wrong move (even though they did work well).
In the spirit of putting the data where our analysts are, we decided instead to change course and use Google Sheets as the underlying database.
This unsophisticated move gave us the ability to natively save and retrieve rows from within AppScript, and meant that at any time, our analysts can snapshot a copy of the spreadsheet and work with the raw data. This includes the url, generated summaries, keywords, date ranges etc.
Furthermore, because of document versioning, we ended up with reliable backups of the production database. Nice.
We will be honest here and say that we had no idea what to expect from a performance perspective. We had heard rumours of people running their entire business off sheets, but to us, that seemed a little… risky. However, we are pleased to report that performance has been rock solid with exception to the occasional sheet read failure that occurs during timed execution (see our section on lessons and issues below for further details).
How will it hold up in the long term? Well, we simply don’t know yet. But for now, reading, writing and searching the sheet is stable and fast within the spreadsheet itself as well as our chat and app interfaces.
And because analysts love CSV files, if we do have to move to a ‘real’ database again, we are confident we could develop a reliable import process from the original sheet.
You mentioned the app interface?
We can’t reasonably expect our staff to work within a chat interface all day, so we needed an interface.
Given the same reason why we focused on using Google Workspace to reduce admin overhead, we wanted a solution that would reduce code writing and maintenance overhead. Nimbot already had approximately 2000 lines of TypeScript (including its test suite) and that’s about as much as we wanted to manage for this project. It is an experiment, after all.
In order to provide an app interface for both desktop and mobile, we have used Google AppSheet, a no-code acquisition Google made a while back.
Inspired by this post regarding investigation timelines, we fired up AppSheet and pointed it at a copy of our database.
This turned out to be a seamless process, done in minutes not hours. Creating an app from nothing with AppSheet generally follows the following workflow:
- Connect and annotate your data source (in our case, a Google Sheet);
- Modify the pre-generated views to make sense for the data you’re handling;
- Publish the application to users. Either as a published app for a cost, or via the AppSheet mobile application with a home screen bookmark.
This resulted in the creation of Nimbot on the Go. NimGo.
NimGo enables us to manage SporeCore from any authenticated device. This includes adding new entries, modifying and refining existing entries as well as removing entries.
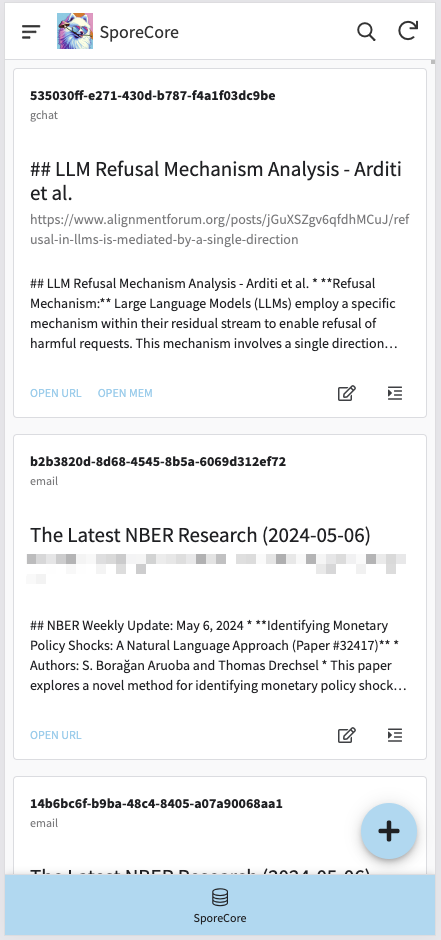
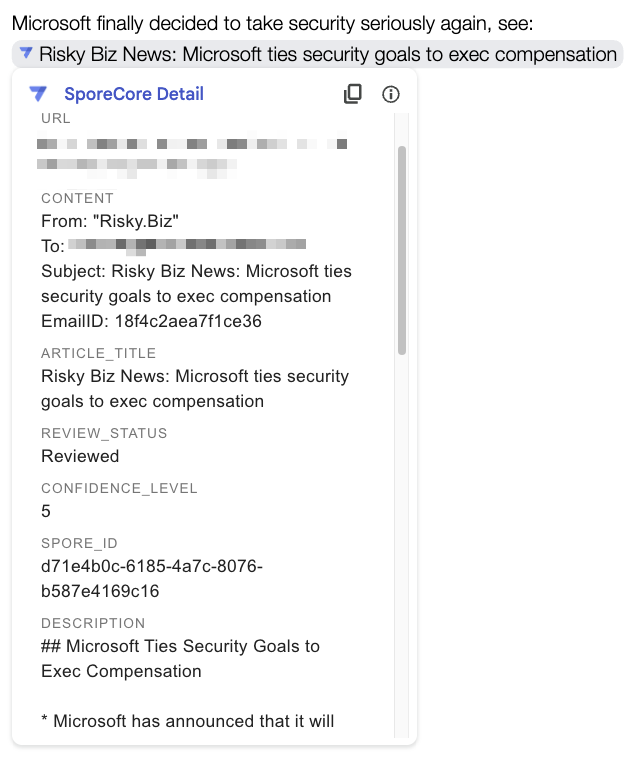
Finally, in addition to being a great standalone application for SporeCore management, it enabled us to implement smart chips for our internal documentation. At any time, we can tag an entry into the document. For example:
30 Seconds
In the context of a program executing, 30 seconds is a long time.
Waiting sucks. This is why ChatGPT and similar AI solutions give immediate feedback as they execute rather than deliver the final result at the end of execution - sitting and waiting for something to run can be frustrating and annoying.
Within Google AppScript, you have a 360 second (6 minute) execution window for your code. That is, unless it is executing in response to a Google Chat request. In that context, you have 30 seconds.
This mostly undocumented limitation appears to be related to user experience, and rightfully so. Expecting a user to wait an extended period of time is unreasonable. The problem we face here is that in the age of no-code glue and AI executing on a bank of H100’s, 30 seconds to a minute can often be considered ‘fast’.
As we deployed, we routinely hit the 30 second limit when processing certain sources. These were generally longer web articles or PDFs. The primary ‘cost’ to us for execution was twofold - First, the processing of longer token requests via Gemini APIs (which, at the time of development were in preview) and secondly the precursor handling of data before summarisation.
For example, in instances where a user submitted a PDF (either via URL or attachment), we convert the PDF to a text-based document format. This enables us to summarise the contents of the PDF without relying on AI vision functionality. Unfortunately for us, that conversion time can be costly and blow out our 30 second processing window.
To solve this, we had to get a little creative and move certain commands (such as /save and /summarise) to asynchronous execution.
Google AppSheet is pretty limited in its runtime execution configuration. So we hacked up an asynchronous queue system with another Google Sheet. When a user submits a longer request, the request is queued within the creatively named Nimbot Queue sheet. This queue entry includes the original request, the space where the request originated from, the user requesting it and a few other metadata entries to ensure we can return a good result to our analyst.
A secondary process then executes at regular intervals looking for new tasks on the queue. Because this trigger is outside of the Google Chat interface, it means we have 6 minutes of execution time to complete the task which is plenty.
Once the task is finished, we return the response to the user via the channel or DM that they initiated the request from using the Google Chat API.
Limitations? Yep. We got ‘em.
At the beginning of this project we had a really simple goal - Bring the data to the analysts’ environment.
The proof of concept service does exactly that and generally with very few issues. About 2000 lines of code, a sprinkling of no-code via AppSheet, a few Google Sheets and we have successfully implemented a system where analysts can easily save, modify and delete entries in our intelligence database.
At any time, the analyst can snapshot the entire underlying data and process it in their favourite tooling. We also ensure that emails get sucked up without issue. Not bad at all.
As nice as it all is, there’s a number of harsh lessons that we have had on the way. It’s clunky and still very much a proof of concept. Some of the key issues we’ve identified along the way include:
Google AppScript runtime fails randomly, a lot, for no apparent reason.
We routinely get seemingly random errors such as Unreachable Service: chat, Exception: Service Spreadsheets failed while accessing document with <sheetId> and Exception: Too many simultaneous invocations: Spreadsheets.
The black box nature of the service means we have no idea why a failure happens and likely never will. Ideally, we would be leveraging similar functionality on Open Source platforms in the future.
The AppScript IDE is terrible.
At best, it would routinely wipe out code changes you’ve made if you open the same window in a different tab. The syntax highlighting would routinely mess up. It would fail to save on certain syntax errors, but not others.
In short: it feels like an afterthought.
To work around these issues we largely developed our code in our own editor and copy and pasted it over. This is a horrible development experience, but was safer than having code wiped out from under us.
Debugging a chat application is a real adventure.
The AppScript IDE includes a basic debugger, and it works as advertised on simple scripts. It’s definitely less powerful than one would want if doing any serious work.
We ended up developing fun functions such as logWithFunctionName() to better debug the application as we went. Yeah, we debugged with the equivalent of well placed print statements.
Managed deployments? Hah!
We would love to say that we had a nice GitHub action which on commit, kicked off some actions and diligently deployed an updated version of our bot to the AppScript environment.
We didn’t.
There is apparently meant to be a way to do this, but we couldn't find out reliably if it’s a supported solution, how it works with HEAD deployments (a requirement given the convoluted way that Google Chat API integrations work with AppScript) and even if it did work, what rollback would look like.
So we skipped it and deployed it by hand. Via the IDE. Unmanaged. Le gasp.
There is the very real and high possibility that AppScript will be killed by Google in the near future.
Releases are happening, but there appears to be no excitement with the project. It almost feels like it’s in maintenance only mode.
This makes sense, we think, because there is a high chance that for the automation that AppScript currently provides, Google is likely hoping that many of the tasks may be handled by Google Gemini for Workspace in the future.
Conclusion
For this effort wanted to explore the hypothesis of bringing data to the analyst, instead of the other way around.
So how does it hold up?
For us - really well.
Admittedly, it’s only been in use for 3 - 4 months since it’s initial development, but in that time the only significant changes were to address the 30 second execution limitation we kept hitting with research PDFs.
It has been used extensively in the development of our first set of reports and often serves as a kind of ‘read it later’ service internally.
We have also found being able to snapshot the database into a working copy, the ability to create smart chips and to access the database on the go to be very useful features indeed.
To date, it hasn’t really been stress tested in terms of volume, but with exception to the random Google AppsScript errors with timed execution (and retry policies mean they will eventually succeed), we can’t foresee any reasons why this kind of approach wouldn’t scale within larger organisations.
All in all, we think there is immense value in considering the philosophy of bringing data into existing work tools and environments than creation of new ones where it makes sense.